Overview:
What is Document Object Model? How to Apply? With its organized representation of a text as a tree of objects, the text Object Model (DOM) is an essential programming interface for web content. The content, structure, and style of HTML and XML documents may all be interacted with and altered by developers. Scripting languages such as JavaScript can access and modify any aspect of a document, including its text, attributes, and elements, as each section is represented as a node in the Document Object Model (DOM). The content and structure of the document can be updated dynamically with this paradigm, making it possible to create interactive web applications. A vital tool for contemporary web development, the Document Object Model (DOM) allows developers to add, remove, or modify elements and attributes, handle user events, and update the document in real-time.
Understanding DOM Nodes:
JavaScript requires an understanding of DOM (Document Object Model) nodes in order to operate dynamically with web pages. A tree of nodes, each representing a portion of the page’s content (e.g., elements, text, attributes), is how the DOM depicts the structure of a web page. Developers may work with and modify HTML texts programmatically thanks to its tree structure.
A DOM Node: What is it?
In the DOM tree, a DOM node is a single point. Nodes come in a variety of forms based on the type of material they represent. JavaScript’s built-in functions and properties allow you to access, change, and work with objects known as DOM nodes.
Types of DOM Nodes
The types of DOM nodes are commonly divided into the following categories:
- An HTML element (such as <div>, <p>, or <a>) is represented by the Element Node (Node.ELEMENT_NODE). You will interact with these nodes the most.
- The text content inside an HTML element or attribute, such as the text inside a <p> tag, is represented by the Text Node (Node.TEXT_NODE).
- An attribute of an element (such as class=”myClass”) is represented by an attribute node (Node.ATTRIBUTE_NODE).
- Comments are represented by the Comment Node (Node.COMMENT_NODE) in HTML code (e.g., <!– This is a comment –>).
- The complete document is represented by the Document Node (Node.DOCUMENT_NODE) and is often accessible via document in JavaScript.
- Before nodes are added to the DOM, they can be grouped and altered using the Document Fragment Node (Node.DOCUMENT_FRAGMENT_NODE), which is a lightweight, minimum document.
- A DOCTYPE declaration is represented by the DocumentType Node (Node.DOCUMENT_TYPE_NODE) (e.g., <!DOCTYPE html>).
Navigating the DOM Tree
Node attributes allow you to navigate between nodes in the DOM tree:
- parentNode: Returns the parent node of the current node.
- firstChild: Returns the first child node of the current node.
- lastChild: Returns the last child node of the current node.
- nextSibling: Returns the next sibling node of the current node.
- previousSibling: Returns the previous sibling node of the current node
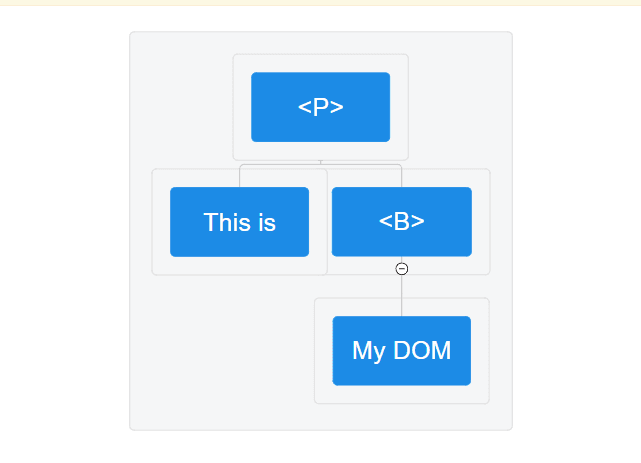
Figure 1 – Showing the Elements in a Tree Presentation
You can see that the B node has one child node while the P node has two in the accompanying figure. As already mentioned, a document can be thought of as a node tree. A document in the node tree view is a group of nodes. On the document tree, the nodes stand in for the branches and leaves. Nodes come in a variety of forms, but the three primary categories are attribute, text, and element nodes.
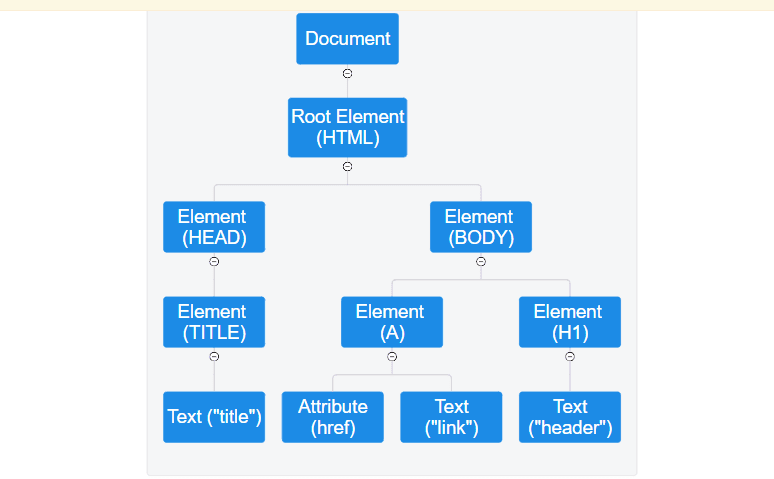
Figure 2 – Displaying the Node Tree of an HTML Document
The following are the main elements of the node structure above:
- The basic components of documents, termed elements, are represented by element nodes. Other elements like HTML, HEAD, BODY, A, AND H1 may be contained within these elements.
- Title 1, link 1, and header 1 are examples of element nodes whose content is represented by the text node.
- Additional details about items are provided by attribute nodes. Element nodes always contain attribute nodes. One example of an attribute node that is part of the body element is href.
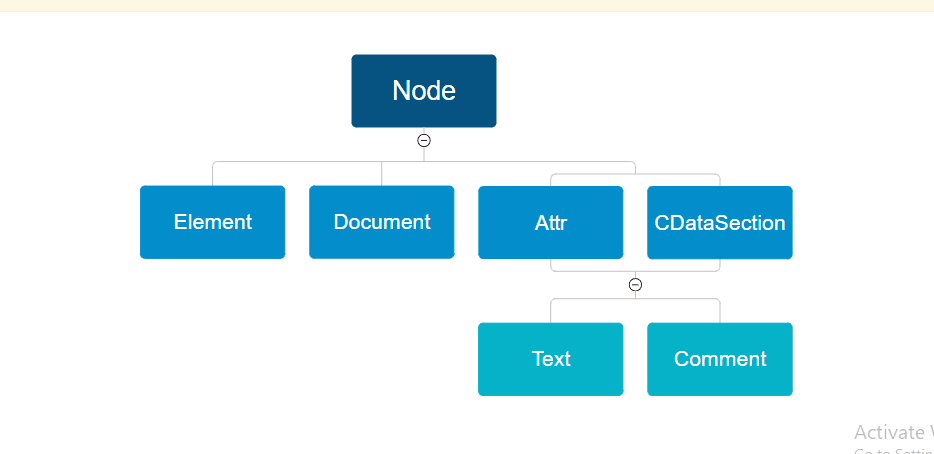
Figure 3 – Displaying the Inheritance Hierarchy for DOM Nodes
Every node in the DOM hierarchy inherits the Node type, as seen in the figure. As a result, the base type for every node in the DOM hierarchy is the Node type. The Node type’s methods and properties are available to all nodes. The base type for Text and Comment types is the CDATASection type, which is comparable to the Node type. Thus, the properties and methods of the CDATASection type and Node type can be used by Text and Comment types.
| Node Type | Numeric Value |
| Element | 1 |
| Attr | 2 |
| Text | 3 |
| CDATASection | 4 |
| Comment | 8 |
| Document | 9 |
Note: Since the node type is a base type and can only offer methods for child nodes, it lacks numeric values. Some of the rules that DOM defines for the child nodes are as follows:
- Make sure there is only one element node as a child node of a document node.
- Make sure that element, text, and comment nodes are child nodes of an element node.
- Make sure the element node has an Attr node connected to it.
- Make sure a text node is a child node of the Attr node.
- Make sure there are no child nodes among the text and comment nodes.
Understanding DOM Levels
A web document’s structure is represented by JavaScript’s Document Object Model (DOM), which is a tree of objects with each node representing an element or piece of content (such as text). The many DOM API versions or specifications that have developed over time are referred to as DOM Levels. These levels enhance and add functionality for interacting with web pages. Below is a summary of each level and the contributions it made to JavaScript:
DOM Level 0
- Early DOM history: Level 0 was the first unofficial JavaScript DOM that was present in early browsers.
- No official specification: There was no official W3C specification for this level.
- Limited functionality: Simple event handling (such as onclick and onmouseover) and basic attributes like document.getElementById() were used.
DOM Level 1
First published in 1998
The purpose was DOM Level 1 was the first version of the DOM that the W3C standardized, creating a foundation for document manipulation in HTML and XML.
key components of DOM Level 1:
Two primary modules comprise DOM Level 1:
- The structure and methods for working with both HTML and XML documents were defined by DOM Core.
- DOM HTML: Focused on particular HTML attributes and elements.
DOM Core API Features
Important interfaces and techniques for navigating and working with a document tree structure were introduced by the Core module. These are the main characteristics:
- Node Interface:
- Node: Each node in the page (element, attribute, text, etc.) is represented by this basic interface in the DOM hierarchy.
- Types of nodes: defines variables such as ATTRIBUTE_NODE, TEXT_NODE, ELEMENT_NODE, and others.
- NodeName, nodeValue, parentNode, childNodes, firstChild, lastChild, nextSibling, and previousSibling are examples of basic characteristics.
- Document Interface:
- Document: Stands for the complete XML or HTML document.
- An element can be retrieved by its ID using document.getElementById(id).
- A list of elements with the given tag name is returned by the function document.getElementsByTagName(tagName).
- A new element node is created using document.createElement(tagName).
- A new text node is created using document.createTextNode(data).
- Element Interface:
- Element: Provides access to an element’s attributes and children within the document.
- Two methods for working with element attributes are getAttribute(name) and setAttribute(name, value).
DOM HTML API Features
This section of the DOM Level 1 specification gave HTML pages particular characteristics and methods:
- HTMLDocument, HTMLFormElement, HTMLInputElement, and other common HTML elements are available.
- HTML form methods include form.submit() and form.reset().
DOM Level 2
First published in 2000
In order to accomplish this, DOM Level 2 included support for advanced document manipulation and event handling, as well as increased modularity for various features.
New Modules in DOM Level 2
- Core: Enhanced version of the Level 1 Core module.
- Events: A strong event model was introduced.
- Style: CSS style handling methods.
- Range and Traversal: Techniques for moving through and picking out certain sections of a document.
- HTML: Additional features for working with HTML documents have been added.
- Views: Made it possible to access many different document views, including the document’s layout and presentation.
Key Features of DOM Level 2
- Enhanced Core Module:
- updated techniques for node access and manipulation.
- Support for namespaces in XML documents (enabling handling of multiple XML vocabularies).
- Events:
- gave all browsers a uniform method for handling events.
- (eventType, listener, useCapture) addEventListener: For an element, register an event listener.
- (eventType, listener, useCapture) removeEventListener: Take an event listener away.
- Event propagation model:
- Capturing phase: The event moves from the root element to the target.
- Target phase: The event arrives at the element that is being targeted.
- Bubbling phase: The occurrence bubbles back up to the root.
- Types of events supported:
- UI events include resizing, loading, and unloading.
- Click, dblclick, mousedown, mouseup, mousemove, and other mouse events.
- When the document structure changes, mutation events are triggered (later versions deprecate this in favor of Mutation Observers).
- CSS and Style Manipulation:
- The CSS Interface’s getComputedStyle(element) function made it possible to view an element’s computed style values.
- style property of the elements: allowed for direct JavaScript editing of inline styles.
- Support for accessing inline styles and dynamically altering styles.
- Traversal and Range:
- Traversal: New API for navigating nodes.
- Using certain criteria, document.createTreeWalker(root, whatToShow, filter, entityReferenceExpansion) enabled iterating through document nodes.
- Another method of iterating across nodes was made possible by document.createNodeIterator(root, whatToShow, filter, entityReferenceExpansion).
- Range: Enabled selecting and manipulating specific parts of a document.
- Range objects are helpful for tasks like text highlighting since they allow you to pick certain sections of a document.
- methods such as extractContents(), selectNode(), and createRange().
- Traversal: New API for navigating nodes.
- HTML Module:
- More HTML-specific interfaces and properties, such as HTMLTableElement, HTMLTableRowElement, and HTMLTableCellElement, are now supported.
- support for HTML form and table-specific DOM manipulation methods.
DOM Level 3
Published in 2004
The purpose is DOM Level 3 added new methods for handling and modifying XML documents and significantly extended the DOM to encompass more complex document processing.
Key Features of DOM Level 3
- Enhanced Core Module:
- enhanced error management, with DOMException included for enhanced debugging.
- Methods for more efficient use of namespaces in XML documents.
- NormalizeDocument() is supported to clean up the document structure.
- Load and Save Module:
- offered a programmatic method for loading and saving XML documents, although it was mostly utilized for server-side DOM implementations and had little browser support.
- XPath Module:
- XPath, a query language for choosing nodes in XML documents, is supported.
- document.evaluate(type, result, resolver, expression, and contextNode): enables JavaScript to run XPath queries directly.
- Particularly in applications that significantly rely on structured XML data, XPath is helpful for complex searches and selection in XML documents.
- Keyboard Events:
- More precise control over how keyboard input is handled is made possible by improved event support that now includes keyboard-related events (keydown, keypress, and keyup).
- Other Enhancements:
- Support for extra document loading and manipulation was made available by Document Object.
- Additional character encoding types are supported to enhance cross-platform and cross-language document compatibility.
DOM Level 4 (Living Standard / Modern DOM)
- Living Standard: Since the W3C discontinued the versioned paradigm for the DOM API, this is a developing standard rather than a static one.
- Dynamic updates: In accordance with browser updates, new features are regularly added and modified.
- New APIs:
- In addition to querySelector,All for a strong selection of CSS-style elements.
- classList.add(), classList.remove(), and classList.toggle() are examples of class manipulation methods.
- Listen to DOM tree changes with the new mutation observer API.
- enhanced event management and the addition of personalized events.
- Web Components and Shadow DOM for enclosed, modular components.
- improvements to input validation and form controls.
- Compatibility: With an emphasis on accessibility and performance, the living standard makes that the DOM API develops in step with the capabilities of contemporary browsers.
Developers now have more control, more potent methods, and interoperability across HTML/XML documents thanks to the evolution of the DOM API. To meet the demands of contemporary web development, the “DOM Living Standard” is being updated with new functionality as needed. The development of dynamic, interactive web applications became simpler with the addition of more potent features at each DOM level. To stay up with the demands of contemporary web development, new features are constantly being added to the DOM Living Standard, which was developed from DOM Level 3.
Understanding DOM Interfaces
Interfaces in the Document Object Model (DOM) function similarly to blueprints for various object types that represent document sections. The attributes and methods for accessing, modifying, and interacting with document elements are defined by these interfaces. Here is a summary of the main DOM interfaces, their functions, and their applications:
The DOMException Interface:
Errors that arise when working with the Document Object Model (DOM) are represented by the DOMException interface. It offers a method for locating particular JavaScript issues and handling them elegantly.
Key Properties:
- name: A string that specifies the kind of error (for example, “NotFoundError” or “HierarchyRequestError”).
- message: An error description that helps with debugging.
- Deprecated code: In contemporary implementations, a name is used in place of the error’s integer code.
Common DOMException Types:
- HierarchyRequestError: DOM tree structure is invalid.
- Attempting to reference a node that does not exist results in a NotFoundError.
- SecurityError: Violation of security restrictions.
- The object is not useable. This is known as an invalid state error.
- QuotaExceededError: Storage limits (like localStorage) have been exceeded.
The DOMException interface facilitates improved error handling and debugging by assisting developers in managing DOM manipulation problems.
| Code | Exception |
| 1 | indicates the INDEX_SIZE_ERR exception |
| 2 | indicates the DOMSTRING_SIZE_ERR exception |
| 3 | indicates the HIERARCHY_REQUEST_ERR exception |
| 4 | indicates the WRONG_DOCUMENT_ERR exception |
| 5 | indicates the INVALID_CHARACTER_ERR exception |
| 6 | indicates the NO_DATA_ALLOWED_ERR exception |
| 7 | indicates the NO_MODIFICATION_ALLOWED_ERR exception |
| 8 | indicates the NOT_FOUND_ERR exception |
| 9 | indicates the NOT_SUPPORTED_ERR exception |
| 10 | indicates the INUSE_ATTRIBUTE_ERR exception |
| 11 | indicates the INVALID_STATE_ERR exception |
| 12 | indicates the SYNTAX_ERR exception |
| 13 | indicates the INVALID_MODIFICATION_ERR exception |
| 14 | indicates the NAMESPACE_ERR exception |
| 15 | indicates the INVALID_ACCESS_ERR exception |
The DOMImplementation Interface:
Methods of creating and interacting with complete documents, separate from the current content, are available through the DOMImplementation interface. It enables developers to produce high-level DOM structures, document types, and other documents that may be used as templates or altered.
Key Methods:
- The function createDocument(namespaceURI, qualifiedName, doctype) generates a new XML document with DOCTYPE and an optional root element.
- createDocumentType(systemId, publicId, qualifiedName): generates a new DocumentType node with the ability to provide a document’s DTD (Document Type Declaration).
- Although it is no longer often used, hasFeature(feature, version) (Deprecated): Verifies whether a particular feature is supported.
When working with XML and creating new documents without changing the current DOM, the DOMImplementation interface is quite helpful.
The DocumentFragment Interface:
An element of the DOM tree can be stored in a lightweight, basic document object represented by the DocumentFragment interface. Because it is not a part of the main document tree, working with nodes inside a DocumentFragment doesn’t result in repaints or reflows, which makes it perfect for enhancing efficiency when doing intricate DOM modifications.
Key Characteristics:
- Temporary Holder: Nodes can be added to the main document in a single operation after being briefly stored in a DocumentFragment.
- Efficient Updates: You may prevent numerous reflows and repaints by creating a structure inside a fragment and adding it to the DOM only once.
- No Parent Node: DocumentFragment only inserts its child nodes into the DOM because it lacks a parent node.
This interface is frequently used for templating or dynamic content loading, and it is particularly helpful for batch DOM manipulations.
The Node Interface:
The Node interface, which represents a single node in the document tree, is a fundamental component of the Document Object Model (DOM). Because the DOM has a tree structure, each element, attribute, text, comment, and document is referred to as a “node.” The fundamental characteristics and functions required to navigate, manage, and work with this tree are provided by the Node interface.
Key Concepts:
- Node Types:
- According to the nodeType attribute, every node in the DOM has a type. In order to distinguish between elements, text nodes, comments, and other elements, the type is represented by a constant.
- Common Node Types:
- An HTML or XML element (such as <div>or <span>) is represented by ELEMENT_NODE (1).
- ATTRIBUTE_NODE (2): Deprecated in current DOM usage, this property is handled by Attr objects.
- The text content contained within an element or attribute is represented by the TEXT_NODE (3).
- A comment in the document is represented by COMMENT_NODE (8), such as <!–comment->.
- DOCUMENT_NODE (9): This node serves as the root of the DOM tree and represents the complete document.
- DOCUMENT_FRAGMENT_NODE (11): This node serves as a lightweight container for other nodes and is employed for batch processing or short-term storage.
- Navigation and Relationships:
- The Node interface provides a way to navigate the tree structure:
- parentNode: Moves to the parent node.
- firstChild, lastChild: Access the first and last child nodes, respectively.
- nextSibling, previousSibling: Traverse horizontally across siblings.
- These attributes facilitate better organized node navigation within the DOM tree without the need for query selectors.
- The Node interface provides a way to navigate the tree structure:
- Properties:
| Property | Description |
| nodeType | gives back an integer value that corresponds to the kind of node. |
| nodeName | gives back the node’s name. |
| nodeValue | gives back the node’s value. |
| attributes | gives back a collection of Attr objects that stand in for the current node’s attributes. |
| parentNode | returns a null value if the parent node of the current node does not exist. |
| childNodes | gives back a collection of node objects that stand in for the current node’s child nodes. |
| firstChild | provides a node object representing the current node’s first child; if not, it returns null. |
| lastChild | returns a node object representing the current node’s final child; if not, it returns a null value. |
| localName | gives back the current node’s qualified name. An element or attribute that is specified as the concatenation of a local name is called a qualified name. |
| namespaceURI | gives back the current node’s namespace URI. |
| nextSibling | returns the node that immediately follows the current node. |
| ownerDocument | gives back the document object associated to the current node. |
| prefix | gives back the current node’s namespace prefix. |
| previousSibling | returns the node immediately preceding the current node. |
4. Methods:
| Method | Description |
| appendChild | adds a new child node at the end of the list of child nodes. |
| cloneNode | Makes a duplicate node of the existing node. |
| hasAttributes | If the node has an attribute, it returns true. |
| hasChildNodes | if the node has child nodes, returns true. |
| insertBefore | Before the current child node, inserts a new node. |
| isSuppoerted | checks whether a specified feature is implemented by the DOM implementation and is supported by the current node. |
| normalize | puts the current node’s sub-tree in the state where the text nodes divide the structural nodes. |
| removeChild | eliminates an already-existing child node from the child node list. |
| replaceChild | adds a new node in place of an existing child node. |
5. Abstract Nature of Node
- The node isn’t instantiated directly. Rather, particular node types, such as Element, Text, Comment, and Document, derive from it.
- In order to maintain uniformity in the way that different nodes are accessed and modified within the DOM, this interface acts as a foundation for shared properties and methods across distinct node types.
The Node interface, which specifies crucial characteristics and methods for interacting with nodes, is necessary to work with the DOM. Node is the ancestor of almost all objects in the DOM tree, standardizing access to and modification of elements, text, comments, and other nodes. The DOM API is incomplete without this interface, making it easy for developers to create and navigate the hierarchical document structure.
The NodeList Interface:
The NodeList interface is a collection of DOM nodes that are usually returned by childNodes and querySelectorAll(). Compared to real arrays, it is less functional yet still looks like an array. NodeLists can be either static (a snapshot that isn’t updated by DOM changes, like querySelectorAll()) or live (they update immediately as the DOM changes, like childNodes). Properties like item(index) to access nodes by index and length to check the number of nodes are supported. You can use for, forEach, or for…of to loop through a NodeList. For complete array method support, you can also convert it to a real array.
The NamedNodeMap Interface:
The NamedNodeMap interface is a group of properties linked to a DOM element that are named-indexed. The attributes property of an element typically returns it with all of its characteristics stored as Attr objects. NamedNodeMap permits indexed access and offers methods to manipulate attributes, but it does not provide methods like map or forEach like arrays do.
Key Characteristics:
- Non-Array Collection:
- NamedNodeMap is an array-like object that can be accessed by index or attribute name, but it is not a real array.
- To determine the quantity of characteristics, it has a length property.
- Access by Name or Index:
- GetNamedItem(name) or an index with bracket notation (map[0]) can be used to obtain attributes.
- Live Collection:
- Since NamedNodeMap is live, any modifications to the element’s properties are automatically reflected.
| Method | Description |
| getNamedItem | finds a node by name in the collection. |
| getNamedItemNS | uses the node’s local name and namespace URI to retrieve it from the collection. |
| item | gives back a collection item according to its index number. |
| removeNamedItem | eliminates a node from the collection according to its name. |
| removeNamedItemNS | removes a node from the collection according to its namespace URI and local name. |
| setNamedItem | uses its nodeName property to add a node to the collection. |
| setNamedItemNS | utilizes the new node’s namespaceURI and localName to add it to the collection. |
The CharacterData Interface:
The Text, Comment, and CDATASection nodes use the CharacterData interface as a base interface to manipulate text content inside DOM nodes. Data, which contains the text content, and length, which shows the number of characters, are among its properties. Text operations are made possible by key methods like appendData(), which adds text, deleteData(), which removes a portion of text, insertData(), which inserts text at a desired location, and substringData(), which retrieves a substring. For the DOM to handle and modify textual content effectively, this interface is necessary.
| Method | Description |
| appendData | adds a string to the current node’s character data at the end. |
| deleteData | eliminates from the current node a range of 16-bit units. |
| insertData | inserts a string at the designated offset of the 16-bit unit. |
| replaceData | substitutes the specified string for the characters beginning at the given 16-bit unit offset. |
| substringData | retrieves a variety of information from the node. |
The Document Interface:
The Document interface, which provides the necessary methods and properties for working with and modifying content, represents the entire HTML or XML document as the root of the DOM tree. With the help of methods like createElement() and createTextNode(), developers can generate new nodes and retrieve elements using getElementById(), getElementsByClassName(), and querySelector(). Additionally, properties like body, head, and title are available through the Document interface, providing access to the main sections of the document. It is essential for dynamically accessing, updating, and structuring web content because it serves as the gateway to the DOM.
| Method | Description |
| getElementsByTagName | returns a collection of element objects with tag names that are comparable to the given name. |
| getElementsByTagNameNS | returns an array of an element object whose value in the name attribute corresponds to the value of the method’s argument. |
| getElementsById | returns the element object with the same id as the argument’s specified value. |
The Element Interface:
In the DOM, an HTML or XML element is represented by the Element interface, which offers properties and methods for working with child elements, classes, styles, and element attributes. Element identifiers, CSS classes, and HTML content are accessible through key properties such as id, className, and innerHTML. The Element interface contains methods for managing attributes, including getAttribute(), setAttribute(), and removeAttribute(), as well as querySelector() and querySelectorAll() for locating child elements using CSS selectors. It serves as a fundamental interface for all HTML and XML elements and is necessary for modifying and interacting with a webpage’s appearance and structure.
| Method | Description |
| hasAttribute() | returns true if an attribute is present in the specified element. |
| getAttribute() | gives back the specified element’s attribute value. This method returns an empty string if the attribute is null and void. |
| setAttribute() | gives the given attribute the specified value. |
| removeAttribute() | eliminates the designated attribute. |
| getElementsByTagName() | gives back an array of element objects with names that correspond to the tagname attribute. If you indicate the value with an asterisk (*), it returns all element objects. |
The Attr Interface:
An attribute in an HTML or XML element is represented by the Attr interface, which gives access to the attribute’s name, value, and relationship to an element. Name, which contains the attribute’s name, and value, which contains its current value, are examples of key properties. The Attr interface is helpful when working directly with attributes as nodes, particularly in XML documents, even though attributes can usually be managed directly through Element methods like getAttribute() and setAttribute(). More precise control over an element’s DOM attributes is possible with the Attr interface.
| Property | Description |
| name | identifies the attribute by name. |
| value | indicates the attribute’s value. |
| ownerElement | gives back the attr object’s element node. |
| specified | returns false if the default value is used to set the attribute, or true if the user has set it. |
The Text Interface:
An element or attribute’s raw text content is contained in a text node in the DOM, which is represented by the Text interface. It derives from the CharacterData interface, offering methods like appendData(), deleteData(), and insertData() for text manipulation as well as properties like data (to access or change the text). Because it enables effective manipulation of text nodes in the DOM tree, the Text interface is crucial for working with textual content within HTML or XML documents.
The Comment Interface:
A comment node in the DOM, represented by the Comment interface, holds textual data in the form of comments (<!– comment –>). Due to its inheritance from the CharacterData interface, it has access to its data property (the content of the comment) as well as methods for changing the text of the comment, such as appendData(), deleteData(), and insertData(). Developers can alter or retrieve comments in HTML or XML documents by using the Comment interface, which is mainly used for working with comment nodes in the DOM. For more examples visit – simple-methods-for-using-document-object-model-in-javascript